All-Weather Deep Outdoor Lighting Estimation — Supplementary Material
This document is an extension of the explanations, results and analysis presented in the main paper. More qualitative and quantitative results are provided for PanoNet. More qualitative predictions on the CropNet are provided on two datasets (HDR outdoor panorama and SUN360) compared with the state-of-the-art approach. In addition, we show the lighting estimation for different viewpoints in a panorama (here) and the ability of changing the predicted lighting (here). All the images used in this file are from our test dataset, our networks (PanoNet and CropNet) never saw these images in the training stage.
Table of Contents
- Lighting estimation for panoramas (PanoNet qualitative evaluation, extends fig. 5)
- Lighting estimation for limited field of view images (CropNet evaluation)
- Lighting estimation for different viewpoints
- Editing light estimation
- Relighting examples
- Visualizing the cues for lighting estimation with Grad-CAM
1. Lighting estimation for panoramas (PanoNet evaluation)
We estimate outdoor lighting parameters from panoramas, and compare our PanoNet method with the state-of-the-art approaches ([Hold-Geoffroy et al.'17], and [Zhang and Lalonde '17]), extending the results for fig. 5 in the paper. Each row shows a different example. The first column shows the input panorama. The second column is the estimated HW sky and LM sky from [Hold-Geoffroy et al.'17](top) and PanoNet (bottom). The renders from left to right are generated with the lighting from [Hold-Geoffroy et al.'17], [Zhang and Lalonde '17], PanoNet and ground truth HDR. Quantitative results can be found in fig. 4 of the main paper.
Input panorama
HW sky and LM sky
[HG et al.'17]
[Zhang and Lalonde '17]
Ours (PanoNet)
Ground truth






































































































































































































2. Lighting estimation for limited field of view images (CropNet evaluation)
We estimate lighting from a single limited field of view image. Each row shows a different example.
2.1. Crop from HDR panoramas
In this section, the input images (first column) are cropped from HDR panoramas, then we estimate lighting parameters with [Hold-Geoffroy et al.'17] and our CropNet. The renders from each approach and the ground truth render from the HDR panorama are shown in different columns. Our approach is able to estimate reliable lighting condition in the cropped image. These results extend fig. 6 in the main paper.
Input
[HG et al.'17]
Ours (CropNet)
Ground truth








































































































































































2.2. Crop from SUN360 panoramas
We estimate the lighting from real images that do not have ground truth, we compare the renders obtained from [Hold-Geoffroy et al.'17] and our CropNet.
Input
[HG et al.'17]
Ours (CropNet)























































































































3. Lighting estimation for different viewpoints
Estimating lighting for different viewpoints extracted from the same panorama. The top row of each video shows the panorama and the cropped region of the input image (bottom left). The cropped image is then used to estimate lighting parameters from the CropNet, the render from the estimated lighting is shown in the bottom right.
4. Lighting edit
We show that with the flexibility of the underlying LM sky model, a user can easily modify the estimated lighting in order to experiment with different lighting effects.
5. Relighting examples
In this section, we estimate lighting from single input image, then we use the predicted lighting to composite a virtual object into the image.
5.1 Relight cars
The following images show different rendering results of a car model under different weather conditions.
Background





Render with CropNet estimation
(mouse hover for [HG et al.'17])





Render with [HG et al.'17]
(mouse hover for CropNet)





5.1 Relight statues
The following images show different rendering results of various statues under different weather conditions.
Background





Render with CropNet estimation
(mouse hover for [HG et al.'17])





Render with [HG et al.'17]
(mouse hover for CropNet)





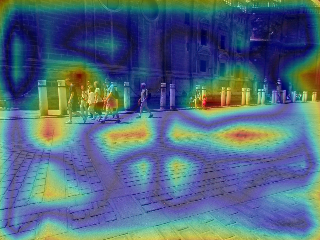
6. Visualizing the cues for lighting estimation
We used guided backpropagation to validate that both PanoNet and CropNet do indeed exploit non-sky regions for their predictions. Our PanoNet thus improves on [H-G'17] which fits the HW model on the sky pixels only. Our approach learns to leverage scene appearance which is an important cue for lighting estimation.
 High
HighColormap used in the Grad-CAM.
6.1 PanoNet
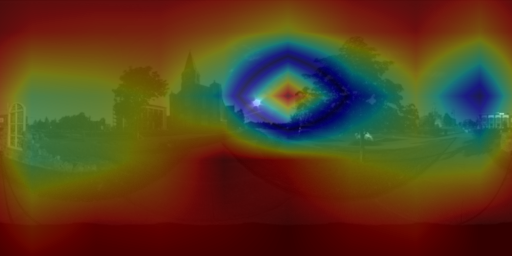
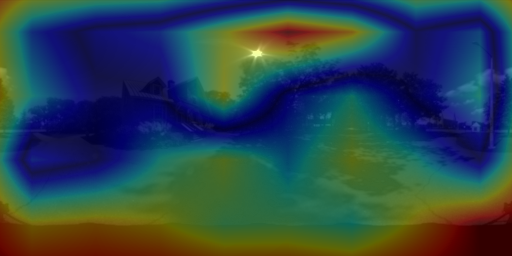
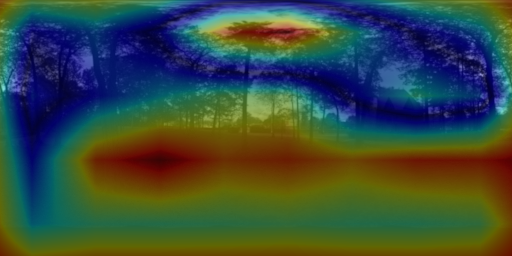
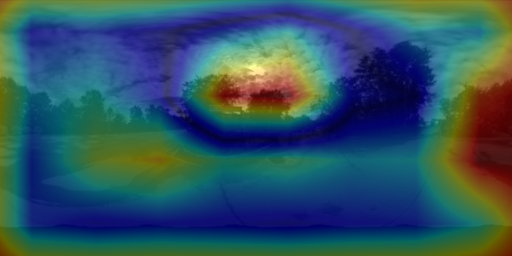
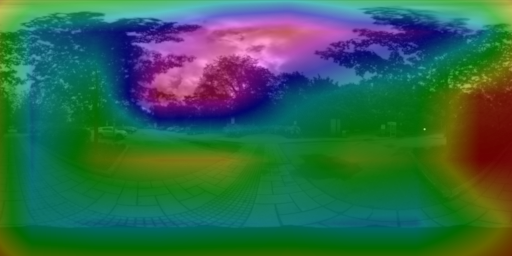

6.2 CropNet