Deep Parametric Indoor Lighting Estimation Supplementary Material
Marc-André Gardner, Yannick Hold-Geoffroy, Kalyan Sunkavalli, Christian Gagné, and Jean-François Lalonde
In this document, we provide additional results and a video to complement the main paper.
In the video we demonstrate the spatially-varying nature of our lighting estimation by moving a virtual object through the scene. As the object moves the shading and shadows change consistently with the location of the lighting, demonstrating the efficacy of our method. We also demonstrate how our parameteric outputs can be easily edited by an artist to achieve different lighting effects.
We also compare our lighting estimates to ground truth EnvyDepth lighting and the results of [Gardner et al. 2017] on a number of example images; we qualitatively evaluate these estimates via visually comparing renders of a generic spiky sphere model under these different lighting conditions. This supplements Figure 5 in the main paper.
We provide all the images used in the user study (Section 4.1), which supplements Figure 8 in the main paper. Finally, we add more examples of bunny relighting (supplementing Figure 10 in the paper) and relighting in stock photos (as in Figure 11 in the main paper).
All the provided examples (images and panoramas) are taken from our test set or from images outside the dataset, which the neural network has never seen during either phase of the training.
1. Demonstration video
In this section, we present a video showcasing two important characteristics of our approach: 1) the ability to represent different lighting conditions depending on the position of the relighted object in the scene, with a single inference pass, and 2) the possibility for a user to intuitively edit the predictions with a simple interface.
2. HDR dataset mosaic
From left to right, we show the input image fed to the network, its prediction (reprojected as an environment map), and an object rendered using A) the Envydepth ground truth, B) the non-parametric method from [Gardner et al. 2017], and C) our method. For both methods, we compute a global scale (across all scenes) to best align the results with the ground truth. This removes the overall intensity that are especially difficult for [Gardner et al. 2017] to estimate.
| Input image | Predicted parameters (IBL) | Render (ground truth) | Render (Gardner et al.) | Render (ours) |
|---|---|---|---|---|
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
| Input image | Predicted parameters (IBL) | Render (ground truth) | Render (Gardner et al.) | Render (ours) |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
3. User study images
In this section, we show all the images used for the user study. For each method (our parametric approach, Gardner et al. 2017 non-parametric method, and Karsch et al. 2014), the render produced using the predicted illumination was A/B compared to another render illuminated with the ground truth lighting. The underlying scene geometry and object materials were the same across all methods. 19 scenes were used in total.
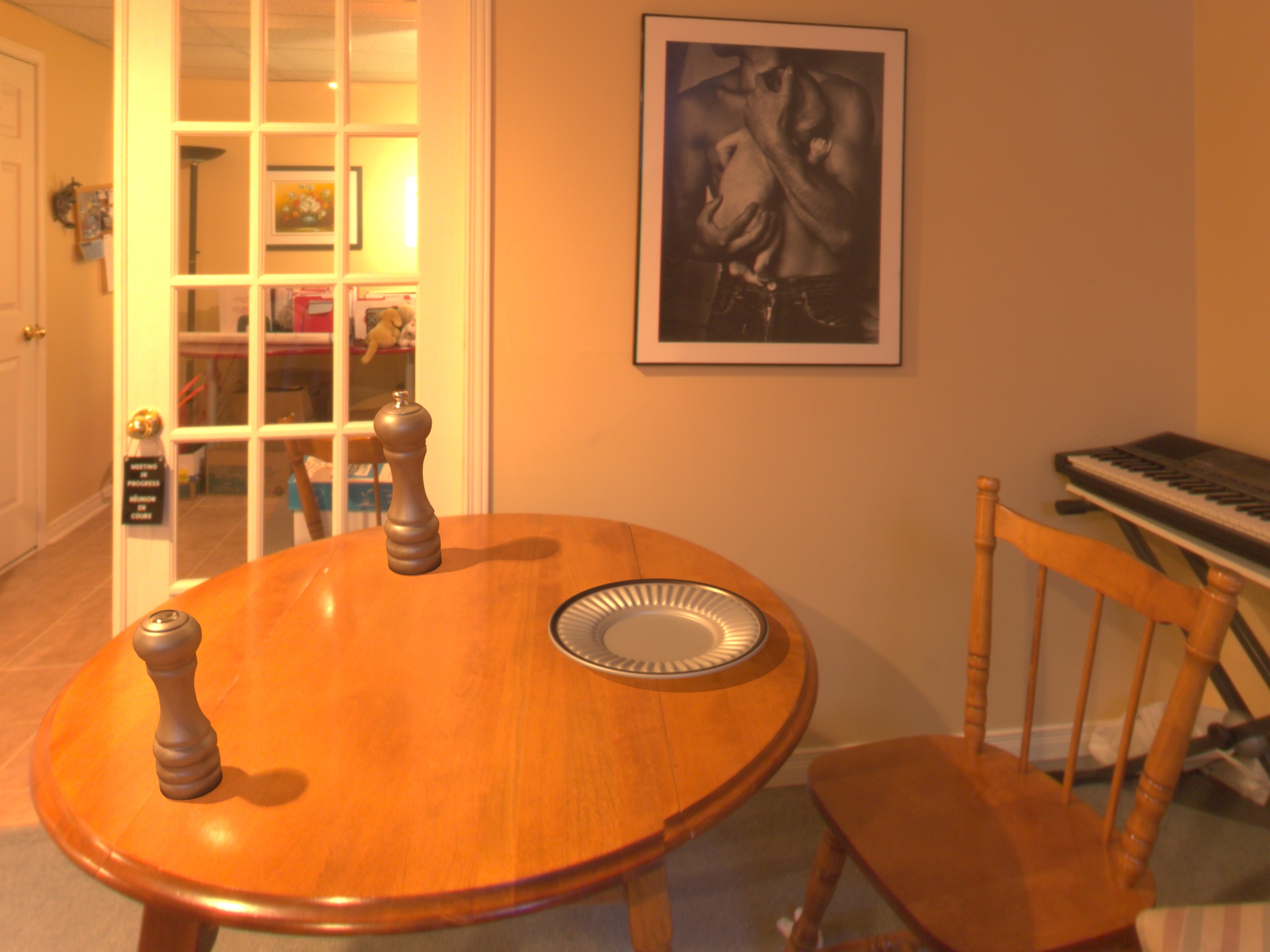
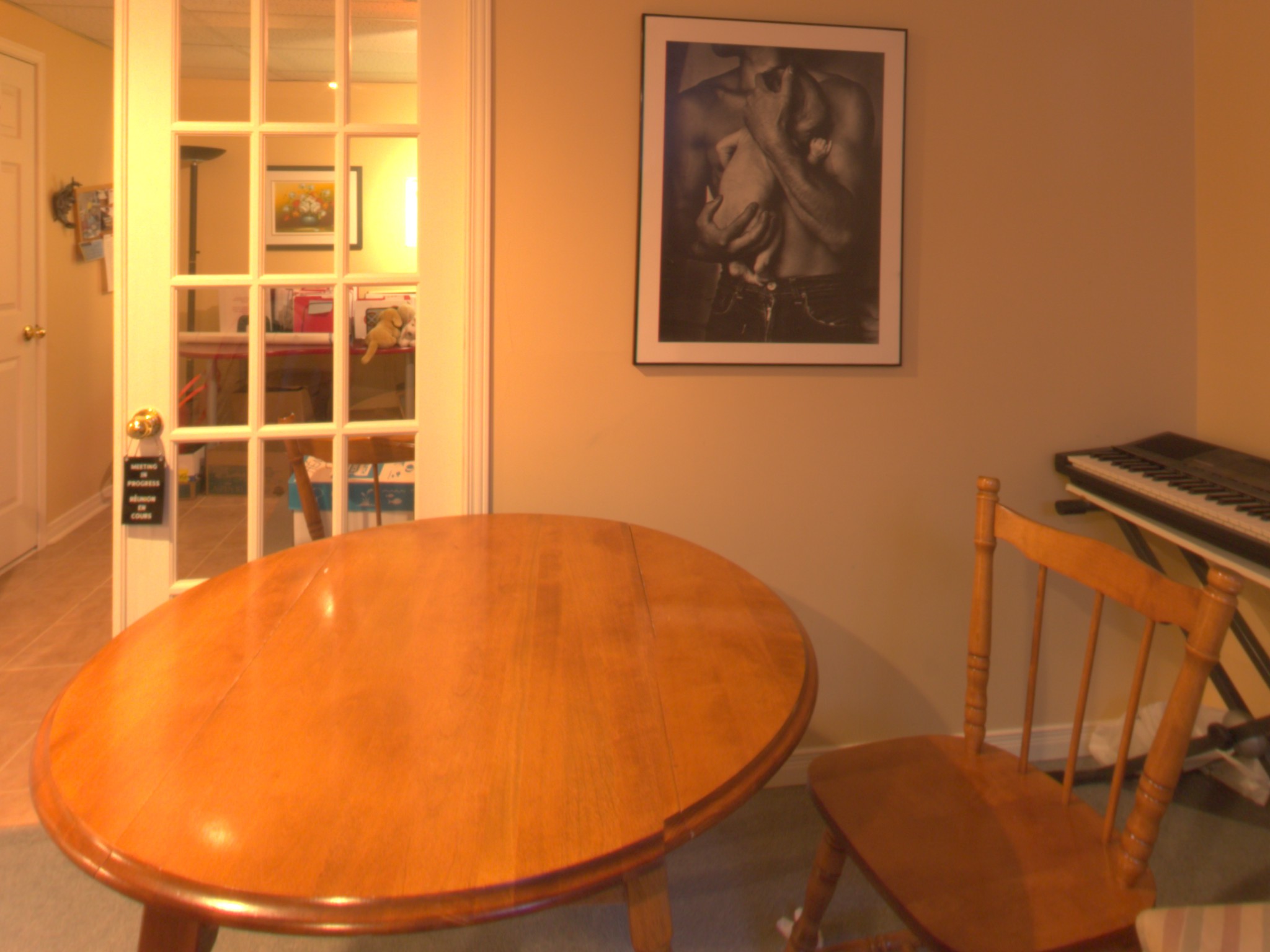
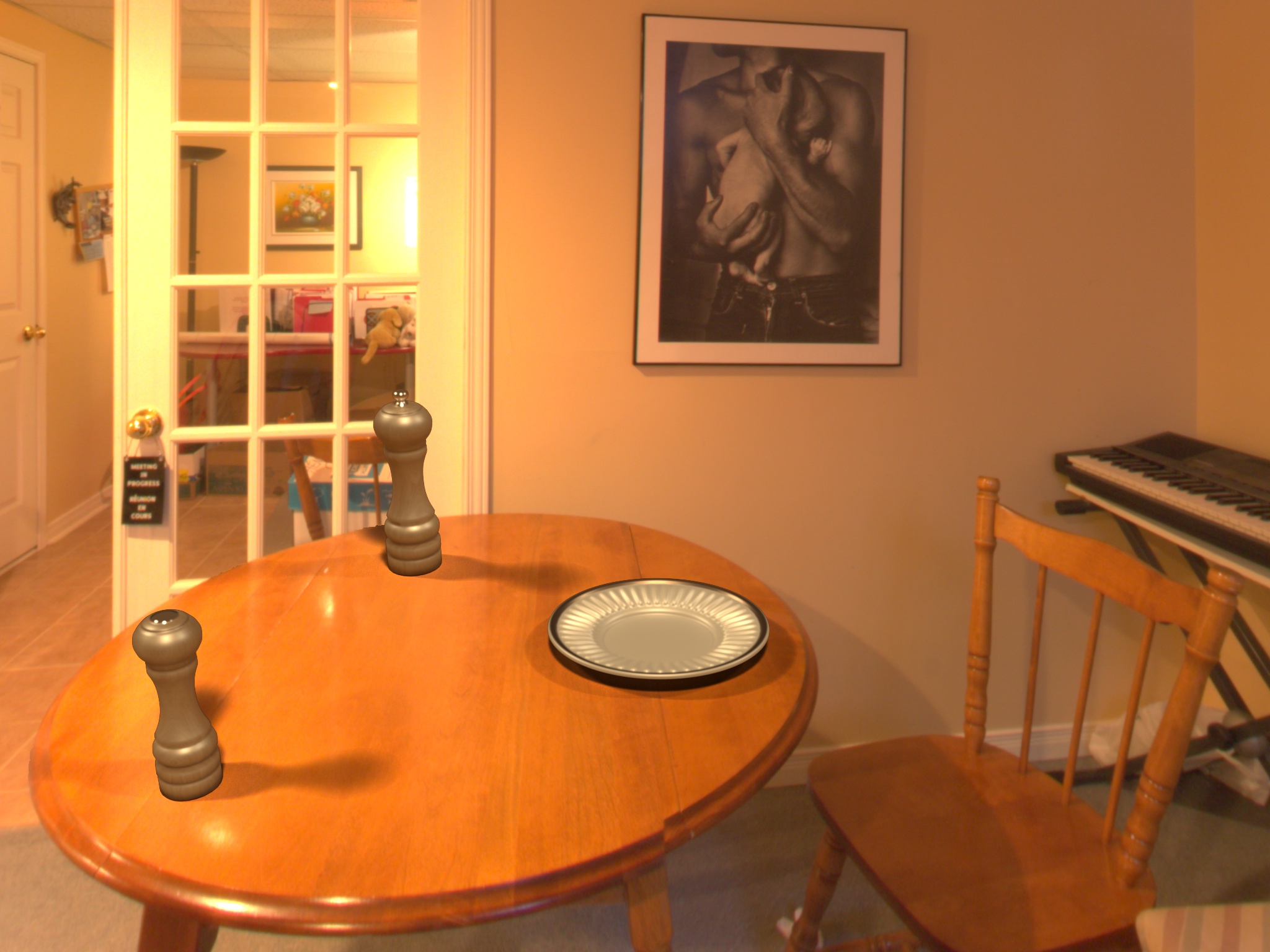
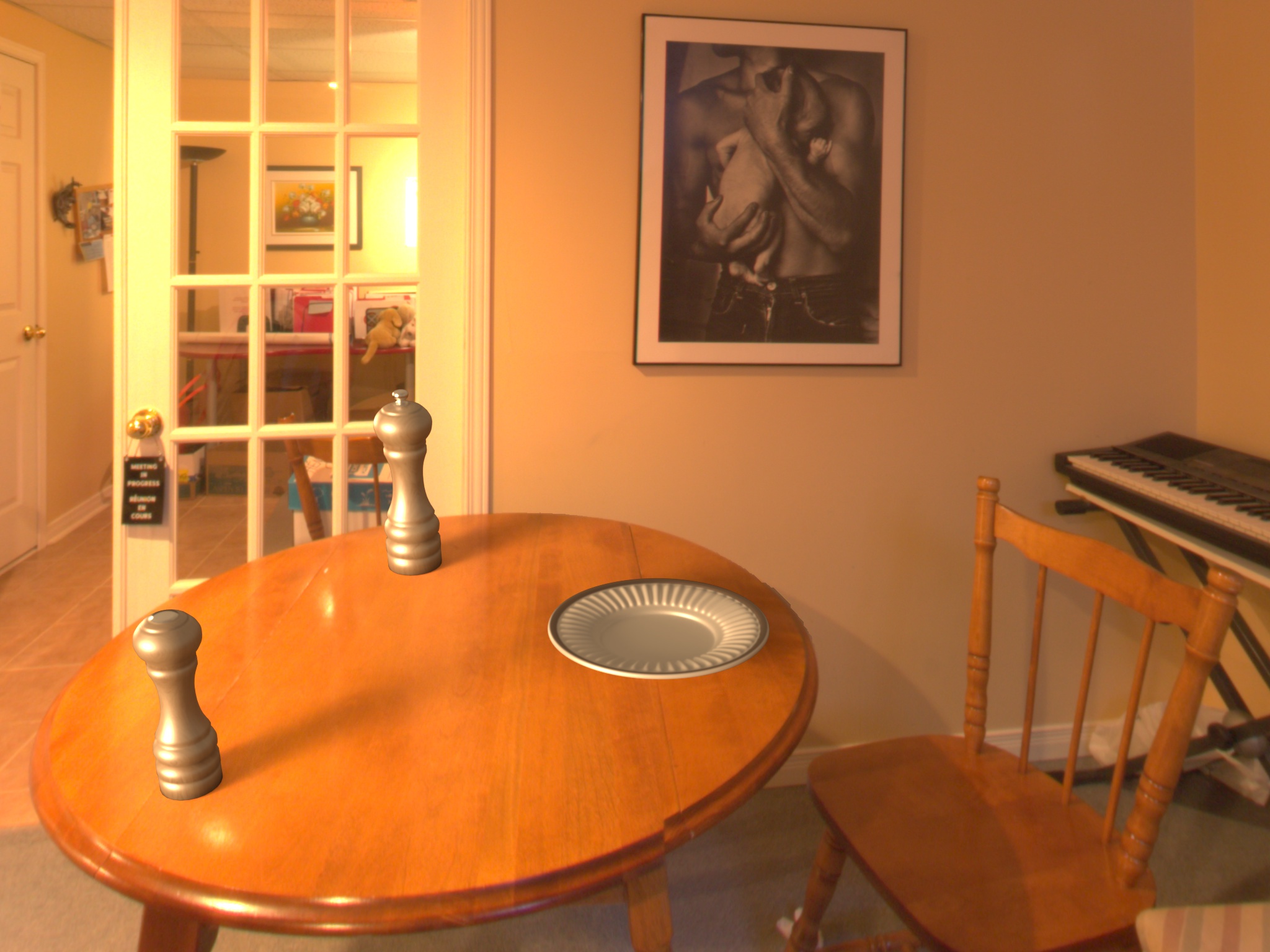



























































































4. Bunny relighting comparison
Each image contains both a real bunny (present in the scene when the picture was taken) and a virtual one (inserted using the illumination predicted by our approach). The pictures are not part of the Ulaval-HDR dataset and were taken using a smartphone (Pixel 2, HDR mode off, automatic focus). The left/right order between the real and virtual bunny is arbitrary for each picture.


















































5. Stock photos results
Relighting results for various stock photos downloaded from the Internet.















