Lens Parameter Estimation for Realistic Depth of Field Modeling
Supplementary material
- Animated compositing, extending fig. 10 and 11 in the paper.
- Dataset generation, extending sec. 4 in the paper
- Defocus quantitative results , extending sec. 5.2 in the paper
- Disparity quantitative results , extending sec. 5.3 in the paper
- Defocus curves, extending sec. 6 in the paper
- Defocus qualitative results, extending fig. 6, 8 and 9 in the paper.
- Disparity qualitative results, extending fig. 7 and 8 in the paper.
- Network architecture, extending sec. 3.3 in the paper
Animated compositing
Our method is the first to enable realistic compositing of virtual 3D objects in defocused images. Here, we show an animation of an inserted skateboard moving through a street image exhibiting a strong depth of field lens effect. On the left, the object is rendered using a camera with an infinitely small aperture, such that it shows no defocus. In the middle, we apply per-frame a uniform blur to the object, by setting the blur diameter following our estimated defocus map (like in fig. 11 of the paper). On the right, the object is inserted in 3D, using a camera with the estimated lens camera parameters as is done in fig. 10 of the paper. The object is rendered using Blender Cycles.
Inserting an all-in-focus object in a defocused image leads to an inaccurate composition. While inserting the object in 2D might give adequate results if the object is small or far away, the results are unconvincing for objects spanning some sizeable part of the background image. The highlighted frame illustrates this phenomenon: the two skateboard wheels exhibit the same amount of blur, even though the blur of the background image at these two locations is wildly different. By contrast, inserting the object in 3D enables taking into account the shape of the object, and rendering it with a physically correct defocus blur. The resulting composited image looks much more convincing, as made evident by the fact that the two wheels now show a defocus matching the background.
Dataset generation
SynthWorld
We use the physically based renderer Blender Cycles to generate images with shallow depth of field from synthetic 3D scenes. We use 67 scenes from Evermotion, in which we manually select camera extrinsics and intrinsics by moving through the scene in the Blender walk navigation mode. We then add random deviations to the camera rotation (sampled from \(\mathcal{U}(-10°, 10°)\) for the roll, \(\mathcal{U}(-10°, 5°)\) for the pitch and \(\mathcal{U}(-10°, 10°)\) for the yaw), and we multiply the focal length by a random multiplicative factor sampled from \(\mathcal{U}(0.75, 2)\).
To choose a focusing depth, we start by rendering a low-resolution depth map of the scene to get the minimum and maximum visible depths. We then uniformly select a depth in this range, which we set as the focusing depth. Finally, to choose a camera aperture, we sample a maximum circle of confusion size from a lognormal distribution (np.random.lognormal(mean=4, sigma=1)), capped at 100 px:

From the depth map and the focal length, we can then calculate the camera aperture which will give the sampled maximum circle of confusion. We add a random environment map lighting from PolyHaven, to which we apply a random yaw rotation between 0 and 360°. We render the image at a resolution of 1200x900 with 512 samples per pixels, before passing it to the Blender denoiser.
This dataset will be made public upon publication of the paper.
BokehMe
We use the BokehMe defocus synthesis method, which generates a synthetic defocus blur on real all-in-focus RGBD images. We apply it to a dataset of proprietary RGBD images, obtained using lidars, stereo cameras and iPhones, and to the DIML dataset. The depth maps are converted to disparity and normalized between 0-1. The BokehMe method takes as input the disparity of focus disp_focus and a blur parameter K, the latter being equivalent to half our blur factor \(\kappa \) (because they work with the radius of the circle of confusion, whereas we work with the diameter). We sample \(d_f\) uniformly in the range [0.05, 1], and \(\kappa\) uniformly in the range [10, 100]. The ground truth (signed) defocus can be computed from the disparity using:
\[c_s = \kappa (d-d_f)\]
Finally, we sample a random gamma value from \(\{3,4,5\}\), and we disable the BokehMe feature that highlights the in-focus part of the image. The code to generate this dataset will be made public upon publication of the paper.
DED
Images from the DED dataset are of low-resolution (613x409), and contain significant JPEG artifacts, as show in the left column. To alleviate this issue, we first deblock the images using FBCNN, a Blind JPEG Artifacts Removal network. The results are shown in the middle column. We then increase the resolution by a factor of two using the Super Zoom neural filter in Adobe Photoshop. The final images, which were used to generate Table. 1, are shown in the right column.
Original image
Deblocked
Deblocked and upsampled












Defocus quantitative results
We show in the following figure the effect of the blur factor \(\kappa\) on the defocus estimation error. The blue curve on the figure shows that the defocus errors (in pixels) increases for images with a wider aperture. However, when normalizing by the blur factor (to account for the fact that an error of 1 px is less worrisome on a blurrier image), we observe that the error is mostly constant across apertures, albeit slightly higher on sharper images.

Disparity quantitative results
We show in the following figure the effect of high defocus on our disparity estimation network, compared to disparity networks trained on sharp images. The shaded areas represent one standard deviation over the mean.

While the performance of our network is consistent across all blur factors, the performance of Ours (pretrained) and MiDaS V3 decreases significantly for images with shallower depth of fields. This shows that estimating depth is more challenging on blurrier parts on images, and that fine-tunning on a proper set of images containing various depth of field effects significantly increases the robustness to blur.
Defocus curves
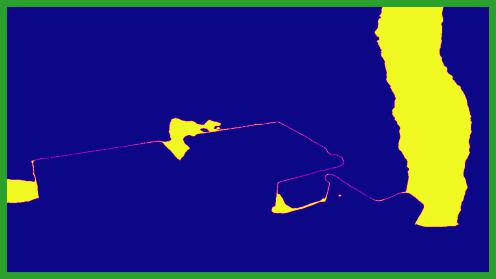
We show an example defocus curve, where we plot the estimated signed defocus as a function of the estimated disparity. This defocus curve can be used to recover the lens camera parameters using multiple methods, as decribed in sec. 6 of the main paper.



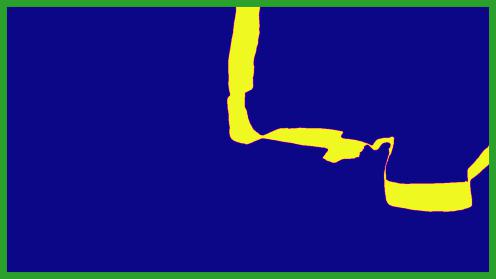



In this example, the ground truth focus disparity is at 0.12, towards the back of the scene. However, the estimated defocus is less accurate in this part of the image (i.e., the scattered points deviate from the ground truth defocus curve, at disparities near 0). These inaccurate points influence the linear fit, reducing the accuracy of the parameters estimation. Our weight network allows to focus on pixels where the estimated defocus is the most accurate, such as edges or textures (e.g. the table tops), while discarding pixels where defocus is less noticeable (e.g. the white walls).
We show more examples below.



























Defocus qualitative results
In this section, we show additional qualitative results of defocus map estimations on all of the datasets, to complement fig. 6, 8 and 9 from the paper. We show 20 images per dataset, selected at random.
In the wild images
Image
DMENet
DBENet
DEDNet
JDD
Ours
Ours, rec.





























































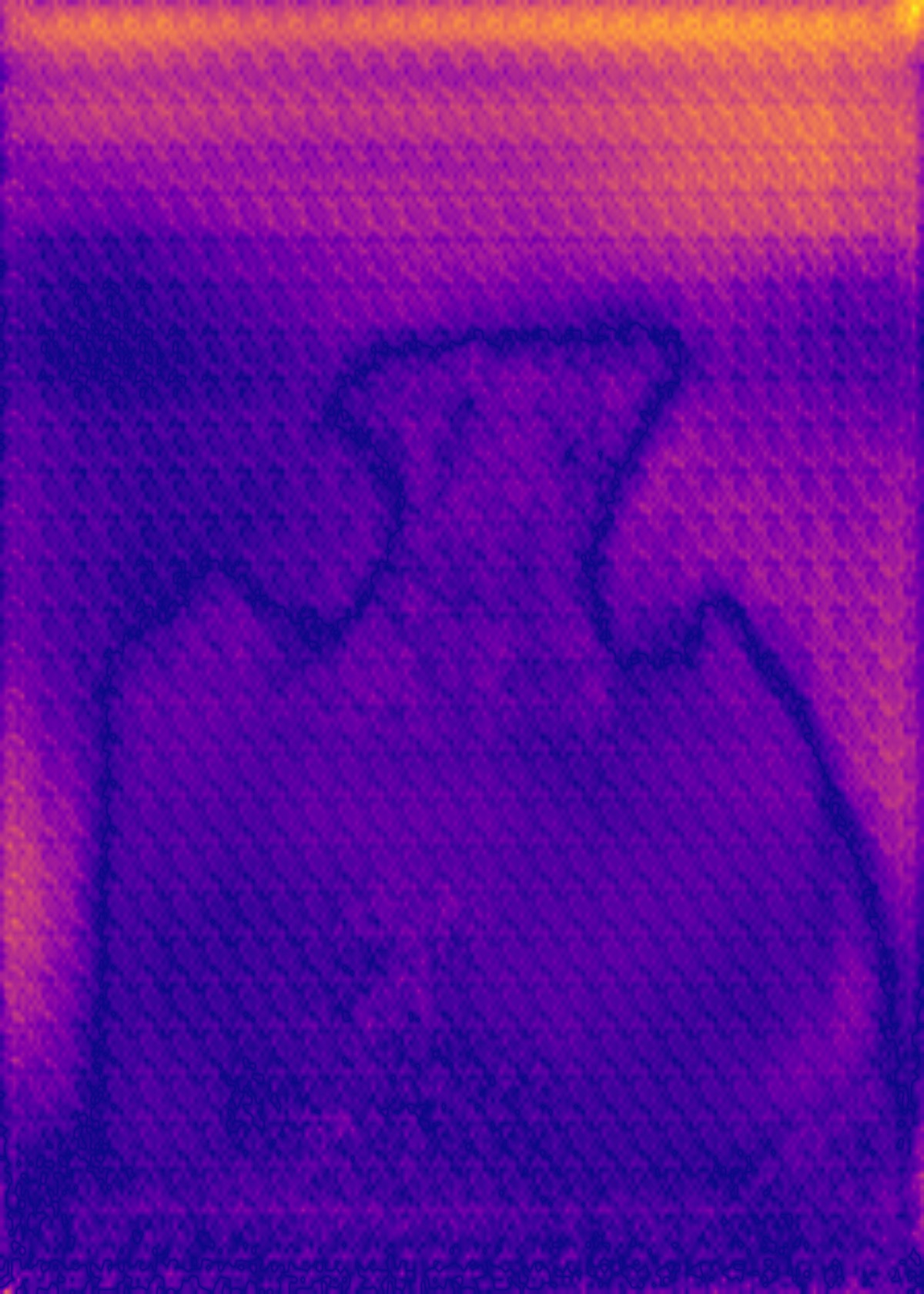




























































Synthworld dataset
Image
Ground truth
DMENet
DBENet
DEDNet
JDD
Ours
Ours, rec.














































































































































BokehMe dataset
Image
Ground truth
DMENet
DBENet
DEDNet
JDD
Ours
Ours, rec.





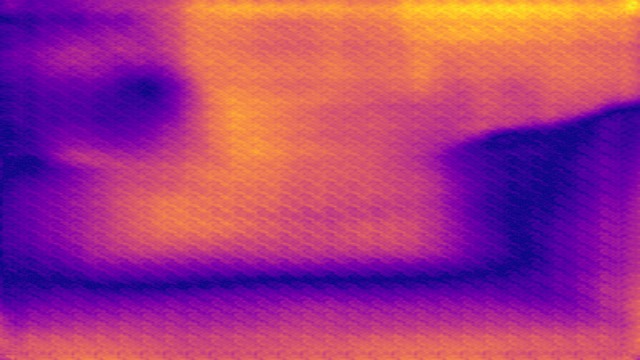







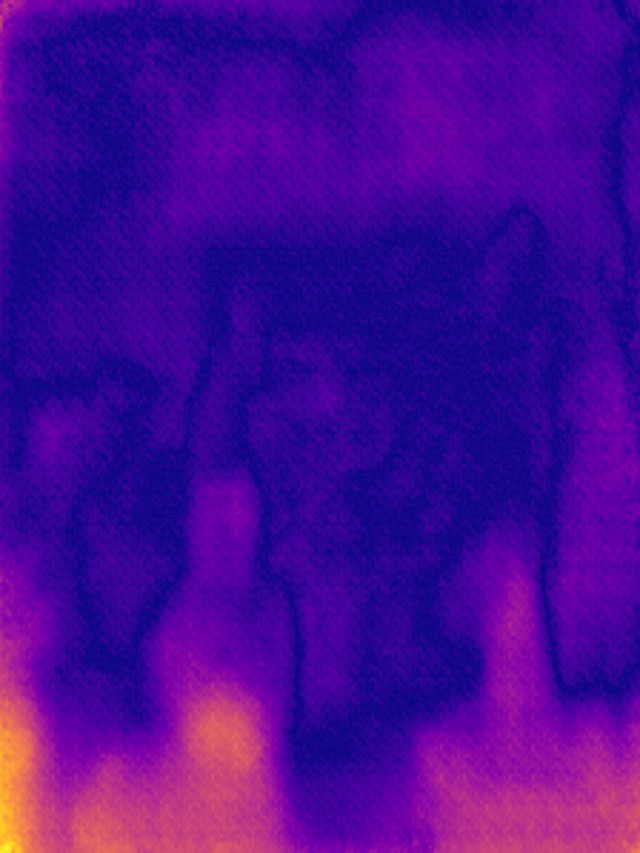







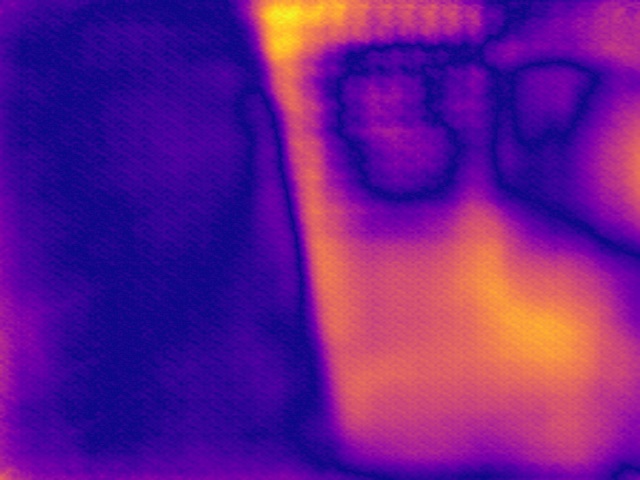























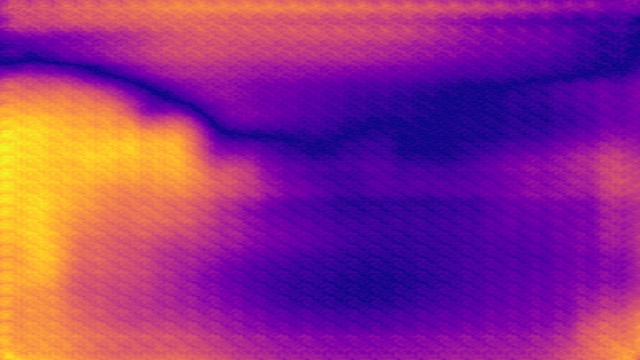















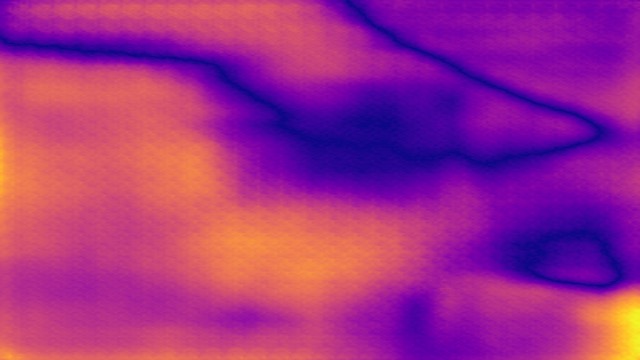




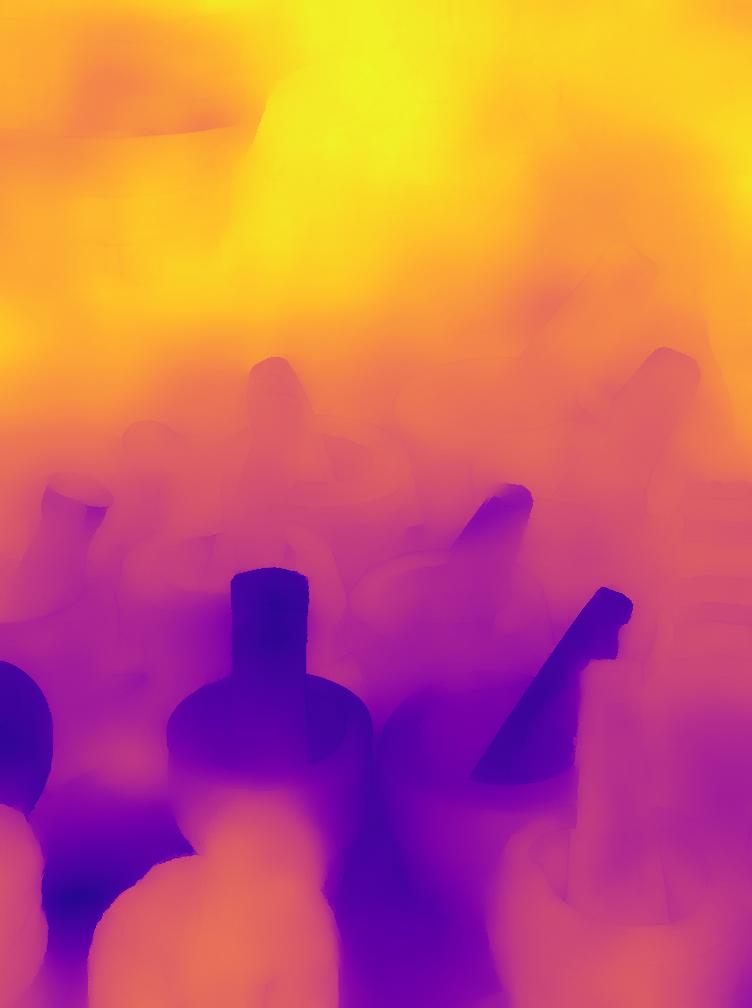

















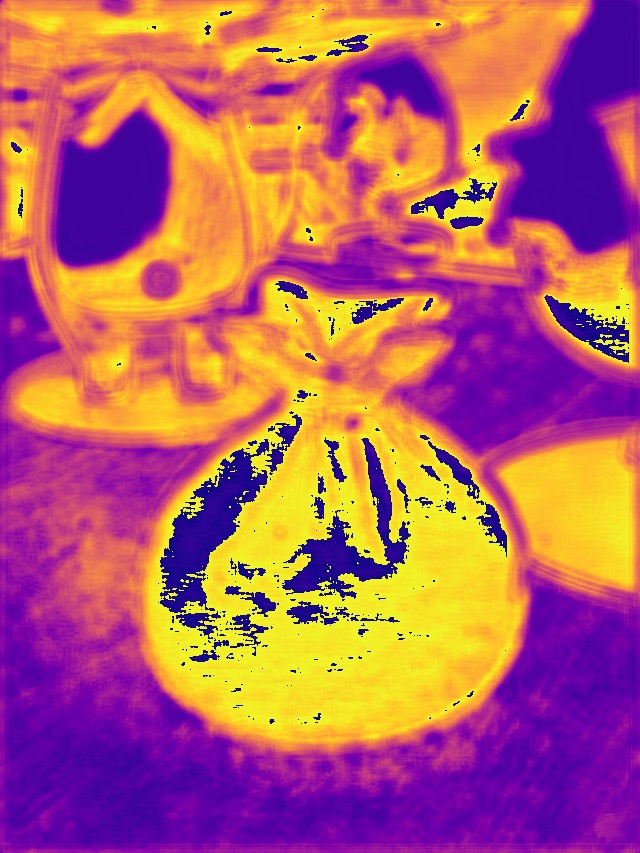
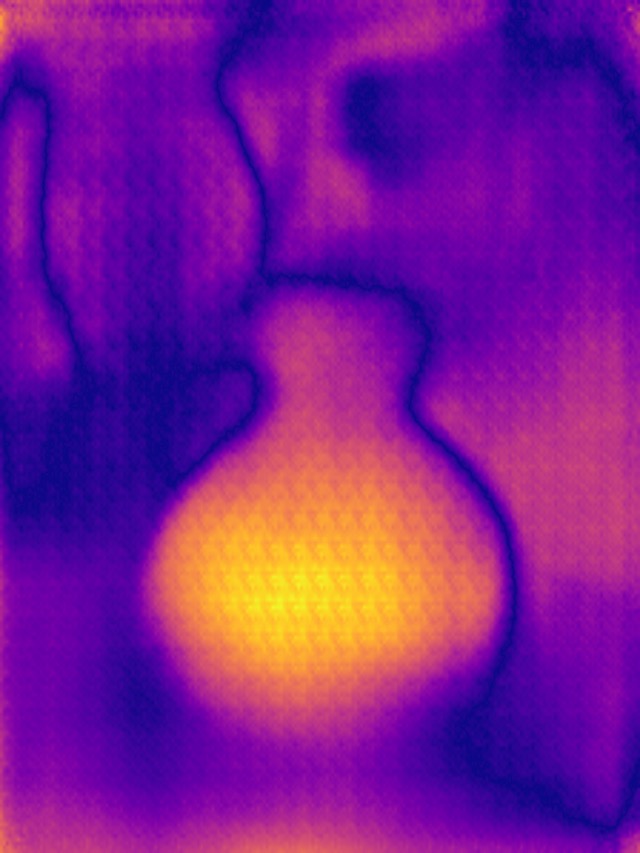























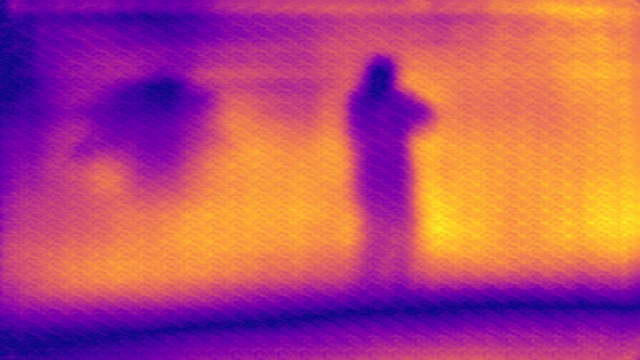















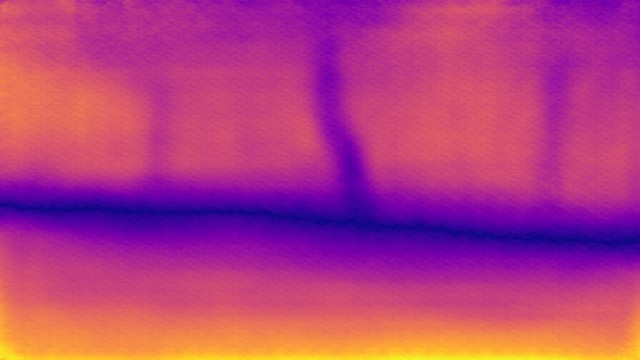





















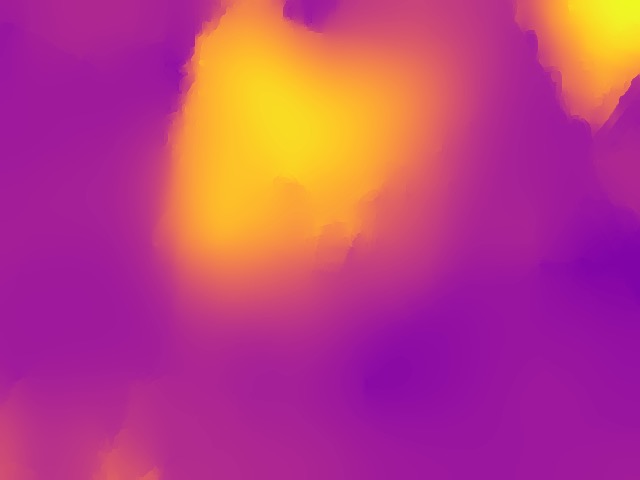

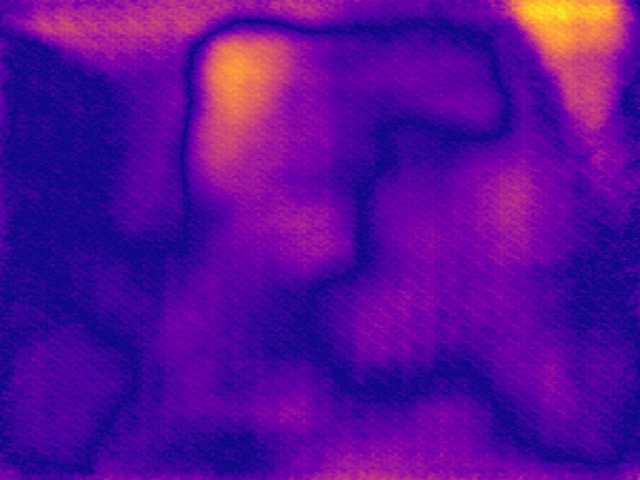


SYNDOF dataset
Image
Ground truth
DMENet
DBENet
DEDNet
JDD
Ours
Ours, rec.































































































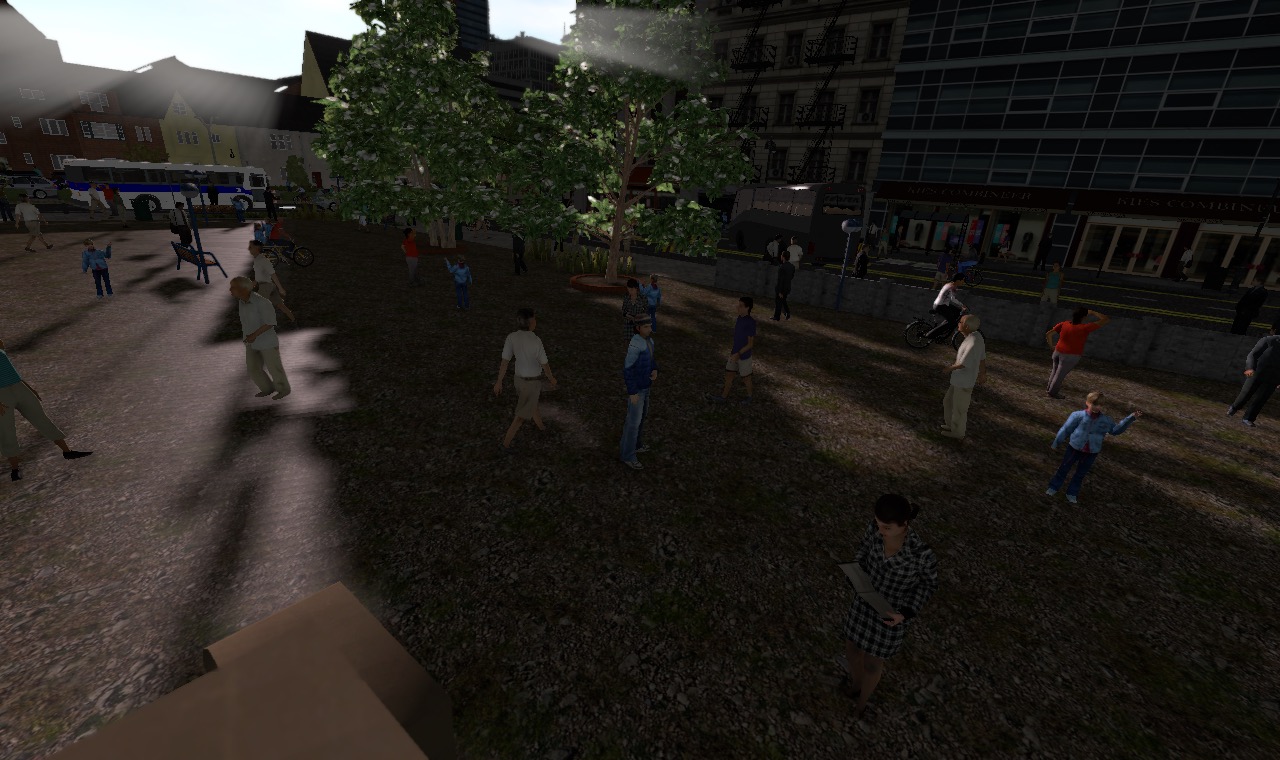


























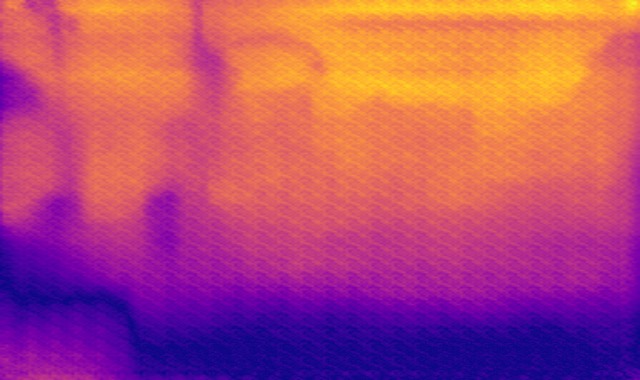






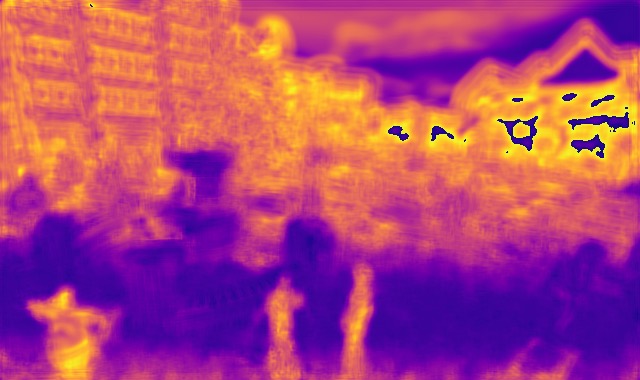
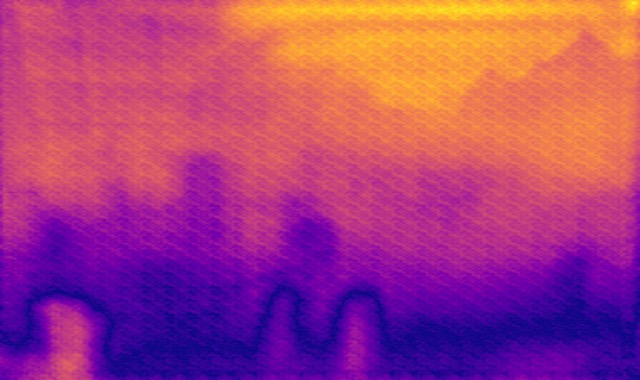





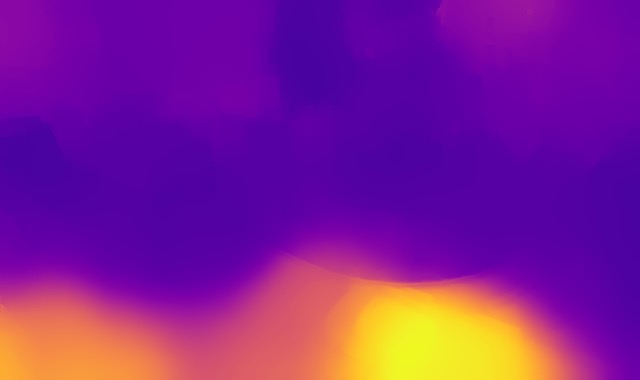




DED dataset
Image
Ground truth
DMENet
DBENet
DEDNet
JDD
Ours
Ours, rec.





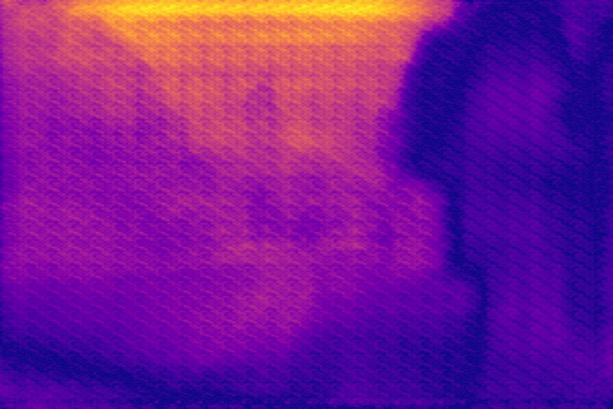




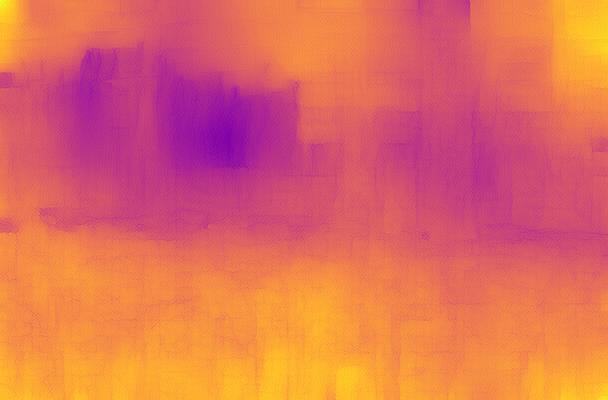
















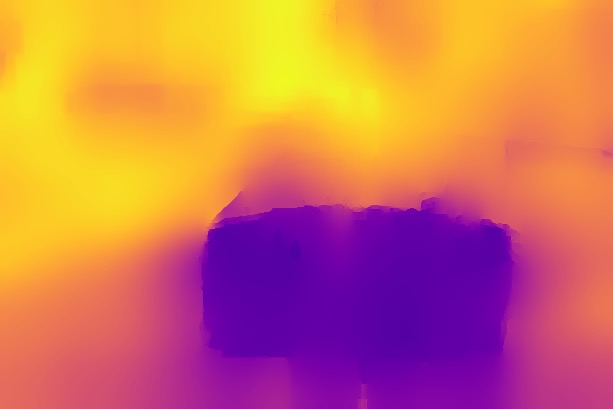

















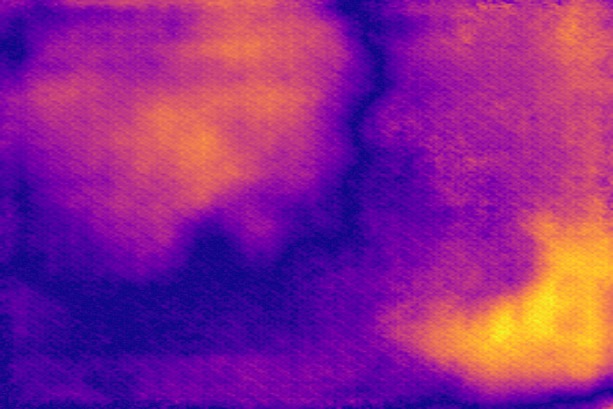






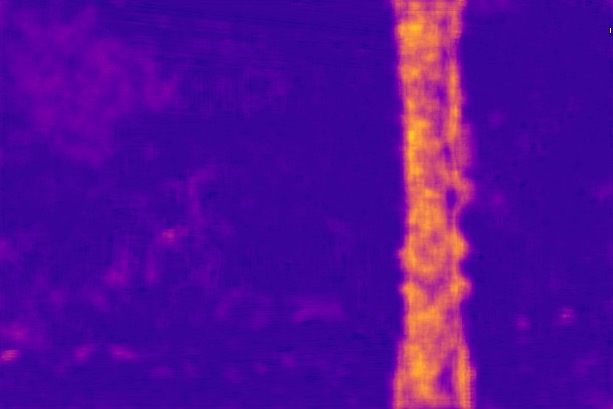
































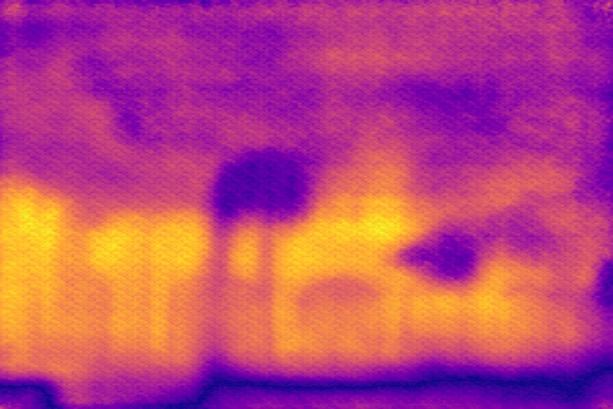































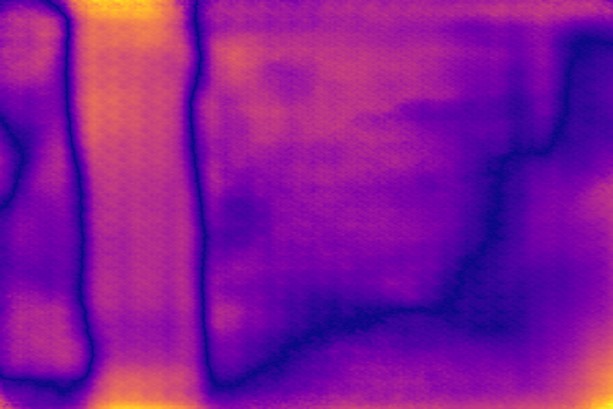















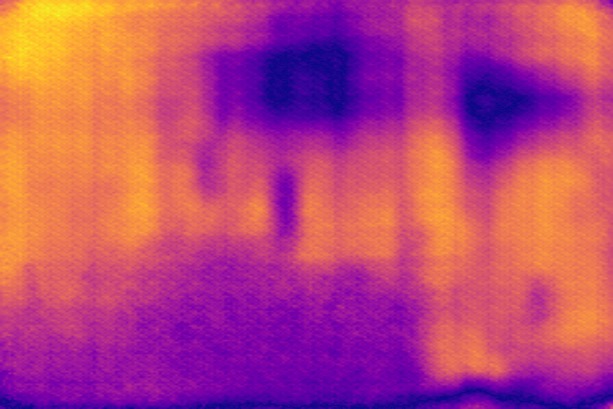

















Disparity qualitative results
In this section, we show additional qualitative results of disparity map estimations on all of the datasets considered, to complement fig. 7 and 8 from the paper. We show 20 images per dataset, selected at random.
In the wild images
Image
MiDaSv2 (conv.)
MiDaSv3 (DPT)
JDD
Ours (pretr.)
Ours



























































































Synthworld dataset
Image
Ground truth
MiDaSv2 (conv.)
MiDaSv3 (DPT)
JDD
Ours (pretr.)
Ours















































































































BokehMe dataset
Image
Ground truth
MiDaSv2 (conv.)
MiDaSv3 (DPT)
JDD
Ours (pretr.)
Ours
















































































































Network architecture
We use the same architecture for the disparity and defocus modules. As the encoder, we use a Pyramid Vision Transformer (PVT v2) network (pvt_v2_b3), where we remove the classification head. The features are passed to a modified SegFormer decoder head, where the four MLPs are arranged like a U-Net architecture, and are each followed by a (3, 3) convolution layer. The outputs are then fused using a FeatureFusionBlock (FFB).
The input image is also passed through a low level encoder (LLE), consisting of a convolutional layer with a (7, 7) kernel. This output of this low level encoder is concatenated with the output of the last Feature Fusion Block, before being passed through two (3, 3) convolution blocks (CB) and a one (1, 1) convolution layer.

Model summary
Here is the summary output of torchinfo
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Model [1, 1, 640, 640] --
├─pvt_v2_b3: 1-1 [1, 64, 160, 160] --
│ └─OverlapPatchEmbed: 2-1 [1, 25600, 64] --
│ │ └─Conv2d: 3-1 [1, 64, 160, 160] 9,472
│ │ └─LayerNorm: 3-2 [1, 25600, 64] 128
│ └─ModuleList: 2-2 -- --
│ │ └─Block: 3-3 [1, 25600, 64] 350,464
│ │ └─Block: 3-4 [1, 25600, 64] 350,464
│ │ └─Block: 3-5 [1, 25600, 64] 350,464
│ └─LayerNorm: 2-3 [1, 25600, 64] 128
│ └─OverlapPatchEmbed: 2-4 [1, 6400, 128] --
│ │ └─Conv2d: 3-6 [1, 128, 80, 80] 73,856
│ │ └─LayerNorm: 3-7 [1, 6400, 128] 256
│ └─ModuleList: 2-5 -- --
│ │ └─Block: 3-8 [1, 6400, 128] 602,624
│ │ └─Block: 3-9 [1, 6400, 128] 602,624
│ │ └─Block: 3-10 [1, 6400, 128] 602,624
│ │ └─Block: 3-11 [1, 6400, 128] 602,624
│ └─LayerNorm: 2-6 [1, 6400, 128] 256
│ └─OverlapPatchEmbed: 2-7 [1, 1600, 320] --
│ │ └─Conv2d: 3-12 [1, 320, 40, 40] 368,960
│ │ └─LayerNorm: 3-13 [1, 1600, 320] 640
│ └─ModuleList: 2-8 -- --
│ │ └─Block: 3-14 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-15 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-16 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-17 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-18 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-19 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-20 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-21 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-22 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-23 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-24 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-25 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-26 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-27 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-28 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-29 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-30 [1, 1600, 320] 1,656,320
│ │ └─Block: 3-31 [1, 1600, 320] 1,656,320
│ └─LayerNorm: 2-9 [1, 1600, 320] 640
│ └─OverlapPatchEmbed: 2-10 [1, 400, 512] --
│ │ └─Conv2d: 3-32 [1, 512, 20, 20] 1,475,072
│ │ └─LayerNorm: 3-33 [1, 400, 512] 1,024
│ └─ModuleList: 2-11 -- --
│ │ └─Block: 3-34 [1, 400, 512] 3,172,864
│ │ └─Block: 3-35 [1, 400, 512] 3,172,864
│ │ └─Block: 3-36 [1, 400, 512] 3,172,864
│ └─LayerNorm: 2-12 [1, 400, 512] 1,024
├─LowLevelEncoder: 1-2 [1, 64, 320, 320] --
│ └─Conv2d: 2-13 [1, 64, 320, 320] 9,408
│ └─BatchNorm2d: 2-14 [1, 64, 320, 320] 128
│ └─ReLU: 2-15 [1, 64, 320, 320] --
├─SegFormerHead2: 1-3 [1, 1, 640, 640] 19,350
│ └─MLP: 2-16 [1, 400, 768] --
│ │ └─Linear: 3-37 [1, 400, 768] 393,984
│ └─Conv2d: 2-17 [1, 256, 20, 20] 1,769,728
│ └─FeatureFusionBlock: 2-18 [1, 256, 40, 40] 1,180,160
│ │ └─ResidualConvUnit: 3-38 [1, 256, 20, 20] 1,180,160
│ └─MLP: 2-19 [1, 1600, 768] --
│ │ └─Linear: 3-39 [1, 1600, 768] 246,528
│ └─Conv2d: 2-20 [1, 256, 40, 40] 1,769,728
│ └─FeatureFusionBlock: 2-21 [1, 256, 80, 80] --
│ │ └─ResidualConvUnit: 3-40 [1, 256, 40, 40] 1,180,160
│ │ └─ResidualConvUnit: 3-41 [1, 256, 40, 40] 1,180,160
│ └─MLP: 2-22 [1, 6400, 768] --
│ │ └─Linear: 3-42 [1, 6400, 768] 99,072
│ └─Conv2d: 2-23 [1, 256, 80, 80] 1,769,728
│ └─FeatureFusionBlock: 2-24 [1, 256, 160, 160] --
│ │ └─ResidualConvUnit: 3-43 [1, 256, 80, 80] 1,180,160
│ │ └─ResidualConvUnit: 3-44 [1, 256, 80, 80] 1,180,160
│ └─MLP: 2-25 [1, 25600, 768] --
│ │ └─Linear: 3-45 [1, 25600, 768] 49,920
│ └─Conv2d: 2-26 [1, 256, 160, 160] 1,769,728
│ └─FeatureFusionBlock: 2-27 [1, 256, 320, 320] --
│ │ └─ResidualConvUnit: 3-46 [1, 256, 160, 160] 1,180,160
│ │ └─ResidualConvUnit: 3-47 [1, 256, 160, 160] 1,180,160
│ └─ConvModule: 2-28 [1, 64, 320, 320] --
│ │ └─Conv2d: 3-48 [1, 64, 320, 320] 184,384
│ │ └─ReLU: 3-49 [1, 64, 320, 320] --
│ └─ConvModule: 2-29 [1, 32, 640, 640] --
│ │ └─Conv2d: 3-50 [1, 32, 640, 640] 18,464
│ │ └─ReLU: 3-51 [1, 32, 640, 640] --
│ └─Conv2d: 2-30 [1, 1, 640, 640] 33
===============================================================================================
Total params: 62,267,159
Trainable params: 62,267,159
Non-trainable params: 0
Total mult-adds (G): 174.03
===============================================================================================
Input size (MB): 4.92
Forward/backward pass size (MB): 3388.21
Params size (MB): 244.27
Estimated Total Size (MB): 3637.40
===============================================================================================
Model description
Here is the model description
Model(
(backbone): pvt_v2_b3(
(patch_embed1): OverlapPatchEmbed(
(proj): Conv2d(3, 64, kernel_size=(7, 7), stride=(4, 4), padding=(3, 3))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(block1): ModuleList(
(0): Block(
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=64, out_features=64, bias=True)
(kv): Linear(in_features=64, out_features=128, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=64, out_features=64, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(drop_path): Identity()
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=64, out_features=512, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=64, out_features=64, bias=True)
(kv): Linear(in_features=64, out_features=128, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=64, out_features=64, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.004)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=64, out_features=512, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=64, out_features=64, bias=True)
(kv): Linear(in_features=64, out_features=128, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=64, out_features=64, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
(norm): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.007)
(norm2): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=64, out_features=512, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm1): LayerNorm((64,), eps=1e-06, elementwise_affine=True)
(patch_embed2): OverlapPatchEmbed(
(proj): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(block2): ModuleList(
(0): Block(
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=128, out_features=128, bias=True)
(kv): Linear(in_features=128, out_features=256, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=128, out_features=128, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(128, 128, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.011)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=128, out_features=1024, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1024, out_features=128, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=128, out_features=128, bias=True)
(kv): Linear(in_features=128, out_features=256, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=128, out_features=128, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(128, 128, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.015)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=128, out_features=1024, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1024, out_features=128, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=128, out_features=128, bias=True)
(kv): Linear(in_features=128, out_features=256, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=128, out_features=128, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(128, 128, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.019)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=128, out_features=1024, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1024, out_features=128, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(3): Block(
(norm1): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=128, out_features=128, bias=True)
(kv): Linear(in_features=128, out_features=256, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=128, out_features=128, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(128, 128, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.022)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=128, out_features=1024, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1024, out_features=128, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm2): LayerNorm((128,), eps=1e-06, elementwise_affine=True)
(patch_embed3): OverlapPatchEmbed(
(proj): Conv2d(128, 320, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(block3): ModuleList(
(0): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.026)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.030)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.033)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(3): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.037)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(4): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.041)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(5): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.044)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(6): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.048)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(7): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.052)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(8): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.056)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(9): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.059)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(10): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.063)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(11): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.067)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(12): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.070)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(13): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.074)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(14): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.078)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(15): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.081)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(16): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.085)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(17): Block(
(norm1): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=320, out_features=320, bias=True)
(kv): Linear(in_features=320, out_features=640, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=320, out_features=320, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(sr): Conv2d(320, 320, kernel_size=(2, 2), stride=(2, 2))
(norm): LayerNorm((320,), eps=1e-05, elementwise_affine=True)
)
(drop_path): DropPath(drop_prob=0.089)
(norm2): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=320, out_features=1280, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(1280, 1280, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1280)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=1280, out_features=320, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm3): LayerNorm((320,), eps=1e-06, elementwise_affine=True)
(patch_embed4): OverlapPatchEmbed(
(proj): Conv2d(320, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(block4): ModuleList(
(0): Block(
(norm1): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=512, out_features=512, bias=True)
(kv): Linear(in_features=512, out_features=1024, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=512, out_features=512, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.093)
(norm2): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): Block(
(norm1): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=512, out_features=512, bias=True)
(kv): Linear(in_features=512, out_features=1024, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=512, out_features=512, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.096)
(norm2): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): Block(
(norm1): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(q): Linear(in_features=512, out_features=512, bias=True)
(kv): Linear(in_features=512, out_features=1024, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=512, out_features=512, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(drop_path): DropPath(drop_prob=0.100)
(norm2): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(dwconv): DWConv(
(dwconv): Conv2d(2048, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=2048)
)
(act): GELU(approximate=none)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(norm4): LayerNorm((512,), eps=1e-06, elementwise_affine=True)
)
(decode_head): SegFormerHead2(
input_transform=multiple_select, ignore_index=255, align_corners=False
(conv_seg): Conv2d(128, 150, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(linear_c4): MLP(
(proj): Linear(in_features=512, out_features=768, bias=True)
)
(linear_c3): MLP(
(proj): Linear(in_features=320, out_features=768, bias=True)
)
(linear_c2): MLP(
(proj): Linear(in_features=128, out_features=768, bias=True)
)
(linear_c1): MLP(
(proj): Linear(in_features=64, out_features=768, bias=True)
)
(linear_c4_proc): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(linear_c3_proc): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(linear_c2_proc): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(linear_c1_proc): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fusion1): FeatureFusionBlock(
(resConfUnit1): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
(resConfUnit2): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
)
(fusion2): FeatureFusionBlock(
(resConfUnit1): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
(resConfUnit2): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
)
(fusion3): FeatureFusionBlock(
(resConfUnit1): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
(resConfUnit2): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
)
(fusion4): FeatureFusionBlock(
(resConfUnit1): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
(resConfUnit2): ResidualConvUnit(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu): ReLU(inplace=True)
)
)
(conv_fuse_conv0): ConvModule(
(conv): Conv2d(320, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU()
)
(conv_fuse_conv1): ConvModule(
(conv): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(activate): ReLU()
)
(linear_pred_depth_32): Conv2d(32, 1, kernel_size=(1, 1), stride=(1, 1))
)
(ll_enc): LowLevelEncoder(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)